Simple event sourcing for AWS lambdas
Today bushiness environment is very dynamic. Quickly shifting business requirements call for Agile software development, modular architectures and flexibly to concentrate on the functionality of highest business priority. Growing demand for modularity popularized microservices, often implemented using event sourcing and CQRS patterns. Though special frameworks and tools like Apache Kafka could be helpful, essentially event sourcing is quite a simple concept and could be implemented just using, for example, AWS lambdas and DynamoDB.
The central idea of event sourcing is the notion of the event log, which records all what happened in the system, and thus represents the application state. The events log is the elementary, immutable, unique source of truth, from which current application state and convenient data views could be always unambiguously reconstructed. This makes application design more logical, and its constituent parts, communicating only through events, better decoupled.
Lets consider how such system may look like in practice. We may construe our application as a documents processor, where every document belongs to some owner - a microservice with exclusive rights to modify its documents according to some business logic. Each microservice receives commands from users and other microservices and, in response, when necessary, generates updates or "events", stored in immutable event logs.
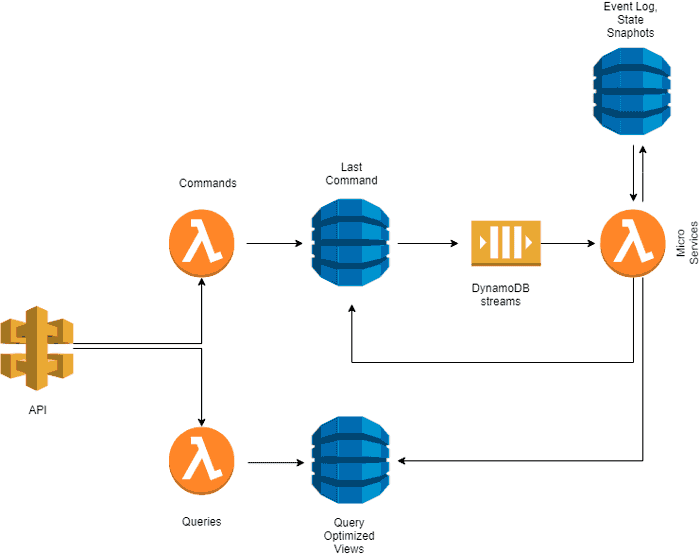
The key part of the architecture is the event log - an ordered list of events processed by microservice. One way to achieve the ordering in AWS - is to use DynamoDB streams. For this we create a commands table, in which every part of the system may write commands (modification requests).
module.exports.addCommand = async event => {
const data = JSON.parse(event.body);
if (typeof data.type !== 'string') {
console.error('Validation Failed')
return {
statusCode: 400,
headers: { 'Content-Type': 'text/plain' },
body: 'Couldn't add command.',
}
}
const params = {
TableName: process.env.COMMANDS_TABLE,
Key: {
microservice: data.type
},
UpdateExpression:"set id = if_not_exists(id, :initial) + :inc, payload=:payload",
ExpressionAttributeValues:{':inc': 1, ':initial' : 0, ":payload": event.body},
ReturnValues: "NONE"
}
// write the todo to the database
await dynamoDb.update(params).promise()
return {
statusCode: 200
}
}
We use serverless framework to bundle our example AWS application. Writing updates to COMMANDS_TABLE, we are able to produce a strictly ordered stream of commands. Leveraging AWS update expressions we get growing id number (set id = if_not_exists(id, :initial) + :inc). These updates later are processed by AWS lambda, subscribed to a DynamoDB stream:
module.exports.example = async event => {
// process all commands
for (const record of event.Records){
console.log(record.eventID)
console.log(record.eventName)
console.log('DynamoDB Record: %j', record.dynamodb)
const sequenceNumber = record.dynamodb["NewImage"]["id"]["N"].padStart(10, "0")
const microservice = record.dynamodb["NewImage"]["microservice"]["S"]
const payload = record.dynamodb["NewImage"]["payload"]["S"]
const params = {
TableName: process.env.EVENTS_TABLE,
Item: {
microservice,
sequenceNumber,
payload
}
}
// some validation, business logic and event logging
await dynamoDb.put(params).promise()
}
return `Successfully processed ${event.Records.length} records.`;
}
Microservice lambdas may do some command validation, data processing, execute some tasks, and update microservice state according to some business logic. And finally microservice should save events (unless command has been already executed) and, possibly, using DynamoDB transactions, state snapshot. As a result requests to other microservices could be generated. Microservice lambda also could be responsible to generate data views (e.g. DynamoDB tables) to efficiently satisfy user queries. To make system even more modular, SNS could be used to notify other subsystems/lambdas, devoted exclusively to data views generation.
The key schema in the commands table governs the system concurrency/scalability. All commands saved with the same key go to the same microservice. In our example we partition commands on microservice name (determined by "type" request attribute), so multiple microservices may reuse the same commands table and may live the same stream lambda. This could be adequate for small enterprise applications, but for more complex systems we may wish to partition commands based on some user/group/organization id. To further decouple system components, we may use different command tables and/or SNS and AWS Kinesis.
Using DynamoDB, we obtain ordered command stream, but by itself DynamoDB can't guarantee commands uniqueness (only once delivery). Thus, to assure idempontence, requests should contain some unique, growing id number, and microservice may wish to check/save the last user request ids. Along these lines, the typical request to our microservice may look like the following:
curl -XPOST https://XXXXX.execute-api.us-east-1.amazonaws.com/dev/command -d '{"type":"microserviceName", "command":"commandName", "id":17, "timestamp":11178, "user":"userId"}'
Event sourcing is an excellent paradigm when one strives to make modular, consistent, and error resilient system. That said, definitely not every application needs it. DynamoDB transactions and conditional updates provide powerful enough tools to handle simple concurrency/data dependencies. But in cases when one needs to handle complex transactional workflows, event sourcing is definitely the way to go. The complete source code of the example implementation of event sourcing using DynamoDB streams could be found on Github.