Face clustering using hierarchical density based methods
Face detection is a desired feature in many applications, ranging from fashion to security. FaceNet is often used for feature embedding in combination with CNN neural networks for face detection. Open source implementations, showing state of the art results on popular datasets, are readily available. As an example, in this blog posts, I take David Sandberg's TensorFlow FaceNet and build a Python package to process videos, extracting face locations, landmarks, and embeddings. Embeddings allow to group face images using new density based clustering algorithms (hierarchical dbscan and umap - density based feature reduction algorithm).
FaceNet and MTCNN
As faces in image may be present in different locations at different scales, to detect them, multi-scale image analyses techniques were developed. The main idea is to check for face presence first on full image. If the test is positive, more detailed tests are repeatedly conducted on smaller image patches. Currently, many libraries provide good face detection implementations, including dlib and opencv. The recent trend is to use neural network based methods as they outperform feature engineering approaches, showing top notch results on test datasets. Here an open source implementation of Multi-task Cascaded Convolutional Networks, available as python package pip install mtcnn, was used. The library is able to both detect multiple faces, and to provide location of faces and face landmarks (nose, eyes, lips, etc).
In addition to face detection, many applications may need to identify people on images. To accomplish this, algorithms extracting image feature are used. Popular FaceNet neural network architecture could be trained to automatically produce feature vectors, called embeddings. During training, algorithm uses trippet loss function encouraging similar embeddings for images of the same people and different embeddings for different people. As mentioned earlier, here a popular open source David Sandberg implementation is being used. The Facenet class is able to load pre-trained TensorFlow models and could be used to generate embeddings.
Video preprocessing
For video/image preprocessing OpenCV library is a common choice. The following simple wrapper simplifies video processing/navigation:
# video_facenet/video.py
class VideoProcessor:
def __init__(self, video_path, **kwargs):
self.video_path = video_path
self.cap = cv2.VideoCapture(video_path)
self.id = 0
self.data = kwargs
@property
def duration(self):
cap = self.cap
fps = cap.get(cv2.CAP_PROP_FPS)
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
return frame_count/fps
@property
def pos(self):
return int(self.cap.get(cv2.CAP_PROP_POS_FRAMES))
@pos.setter
def pos(self, pos):
self.id = pos
self.cap.set(cv2.CAP_PROP_POS_FRAMES, pos)
def images(self, start=0, end=None):
self.pos = start
success, image = self.cap.read()
while success:
if end is not None and self.id == end:
yield image
return
yield image
self.id += 1
success, image = self.cap.read()
def iterate(self, process, start=0, end=None):
last = self.frame_count - 1 if end is None else end
for image in self.images(start=start, end=end):
if process(image=image, pos=self.id, video=self, last=last, **self.data):
break
Flexible data processing is best achieved using functional paradigms. To this end, VideoProcessor's constructor receives additional named parameters, which are then passed further to processing functions (in iterate method). Thus, processing functions should be ready to receive dictionaries of named arguments **kwargs which they may pass down the line, or may just choose to ignore. Following this pattern, image processing could be shaped into interchangeable, reusable functions:
# video_facenet/pipelines.py
def process_video(video_path, model_path, start=0, suffix="", batch_size=64, end=None, **kwargs):
from video_facenet.facenet import Detector, Facenet
detector = Detector()
encoder = Facenet(
model_path=model_path,
batch_size=batch_size
)
faces = []
save = create_faces_saver(suffix=suffix)
def process(save, pos, faces, batch_size, last, **kwargs):
find_faces(faces=faces, pos=pos, **kwargs)
if len(faces) >= batch_size or pos==last:
generate_embeddings(faces=faces, **kwargs)
save(faces=faces, **kwargs)
save.flush()
faces.clear()
print("frame #", pos)
video = VideoProcessor(video_path=video_path, detector=detector, encoder=encoder, save=save, faces=faces, batch_size=batch_size)
video.iterate(process, start=start, end=end)
save.close()
detector.close()
encoder.close()
The process_video function from pipelines.py module detects, encodes and saves images in batches in three separate text .csv files: face bounding boxes, landmarks, and embeddings (bounding_box_suffix.csv, landmarks_suffix.csv, and embeddings_suffix.csv respectively). A suffix is added to the file names to distinguish different jobs. The start and the end of video could be specified, so processing could be easily parallelized.
Clustering faces: HDBSCAN
Information from text files could be processed further using density based clustering techniques. FaceNet could be seen as probabilistic model generating embeddings in multidimensional embedding space. Embeddings of different people should form distinct dense clusters. One of the popular tools to discover such clusters is DBSCAN, which is shown to give good results for face clustering. Recent algorithm extensions/generalizations, like hierarchical DBSCAN, divide densely populated regions into hierarchical trees to automatically find cluster boundaries based exclusively on available density information. An hdbscan is a popular DBSCAN extension, implementing scikit-learn interface and playing nicely with the rest of scikit-learn ecosystem. As you may see below, for sample short Hamilton video, clustering gives nearly ideal results, grouping together faces of different people and even filtering out the noise - erroneous face boxes (dark points on the plot bellow). Results are illustrated using umap (a density based feature reduction library similar to t-SNE):
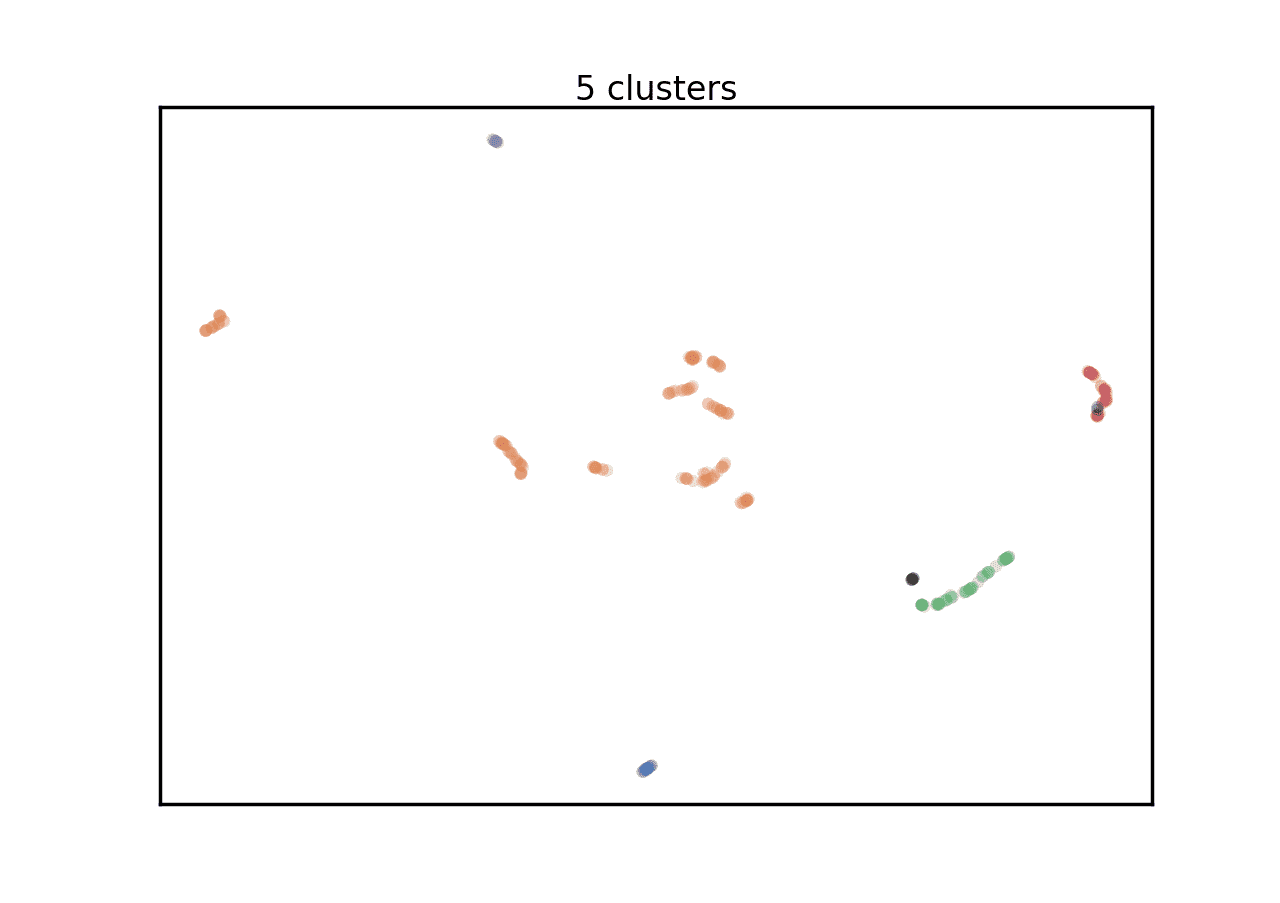
From this plot, it could be seen that points of embedding space tend to cluster into dense groups. Dense regions could be unevenly shaped, which explains why clustering method like K-mean poorly perform on such tasks. Density based clustering clearly gives better results, though results, in general, may be not that good as in this short sample. For example, relatively rare camera angles, lightning conditions or faces may result in outliers, marked by algorithm as noise. On the other hand, after some time, failures in face detection algorithm tend to produce their own clusters. And on some camera angles/with different lightnings, faces of the same people may fall into different clusters. Another problem is that, as number of embeddings grows (to dozens of thousands), the algorithm performance eventually comes to a halt.
To some degree, the mentioned problems could be alleviated. First of all, hdbscan package allows not only to assign cluster labels, but also gives estimates of assignment probabilities (for every point/every cluster combination). Assignment probabilities could be also obtained for points not used during training, which mitigates scalability problems. Furthermore, hdbscan could be used in combination with feature reduction algorithms. In addition to standard PCA, density based umap algorithm could be used. Similar to to t-SNE, umap is based on point densities but is designed to work not only for visualization, but for feature reduction and even supervised learning. Both umap and hdbscan honer scikit-learn conventions, so could be combined into single scikit-learn Pipeline and tweaked using grid parameter search:
# video_facenet/hdbscan_clustering.py
def cluster_faces_pipeline(reduce):
models = []
if reduce:
models.append(
("umap", umap.UMAP(
n_neighbors=30,
min_dist=0.0,
n_components=30,
random_state=42,
))
)
models.append(("hdbscan", hdbscan.HDBSCAN (min_cluster_size=15)))
return Pipeline(models)
Though, in general, 512 dimensions of facenet embeddings carry very useful information, within similar settings all this information is clearly redundant and just contributes to noise and clustering algorithm confusion. Reducing dimensions to the 20-50 components, one may improve both algorithm accuracy and performance, and, as a result, meaningful clusters for videos with thousand faces become a possibility:

As unsupervised learning is often exploratory in nature, it is easier to pass parameters/options using configuration yaml files:
# tasks.yaml
hamilton:
suffix: hamilton
video_path: short_hamilton_clip.mp4
model_path: /lab/20180402-114759/facenet.pb
umap: false
delay: 200
parameters:
hdbscan__min_cluster_size: 5
process_hamilton:
task: process_video
config: hamilton
Here tasks are defined as named objects, a function name is specified in a "task" property, and configuration is either specified alongside or is referenced through a "config" property.
Clustering and other ML algorithms
Clustering algorithms are important in unsupervised/exploratory settings when there are no labeled data, and/or available data should be quickly explored. Thus, frames/images, grouped by clustering algorithms, with probabilities/alternative assignment suggestions, may help to prepare training data for supervised algorithms:
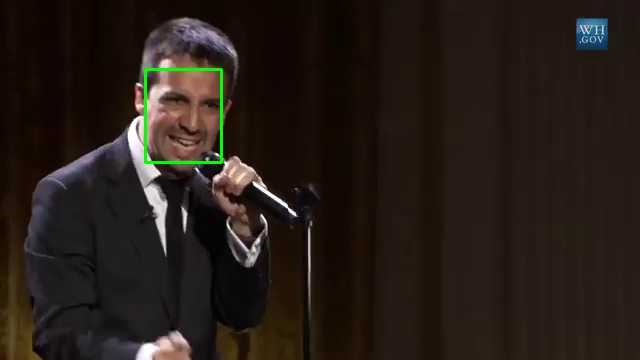
Modern density based algorithms allow for supervised learning/classification. As density based algorithms are completely data driven they can make data processing less susceptible to data drifts. On the other hand, such methods come with a number of inherent shortcomings: they poorly generalize to unseen data and have a limited scalability (all points should be kept in memory, compared to a few parameters of neural networks or SVM). As you can see, in case of face detection/recognition, clustering algorithms favorably complement neural networks, helping to prepare training data/providing flexible identification algorithms.
The source code used in the blog post is available on Github or could be installed through pip install video_facenet.